
MaX applications on EuroHPC supercomputers
MaX lighthouse codes –QUANTUM ESPRESSO, YAMBO, SIESTA, BigDFT and FLEUR— are efficient parallel codes with a demonstrated capability to scale on homogeneous nodes up to several thousand MPI ranks by adopting multiple levels of parallelism. In its third phase, MaX is working to step up the scalability of its lighthouse codes to make them able to exploit efficiently up to several thousand GPUs. At the same time, we continue to add new features, plugins, and data exchange methods.
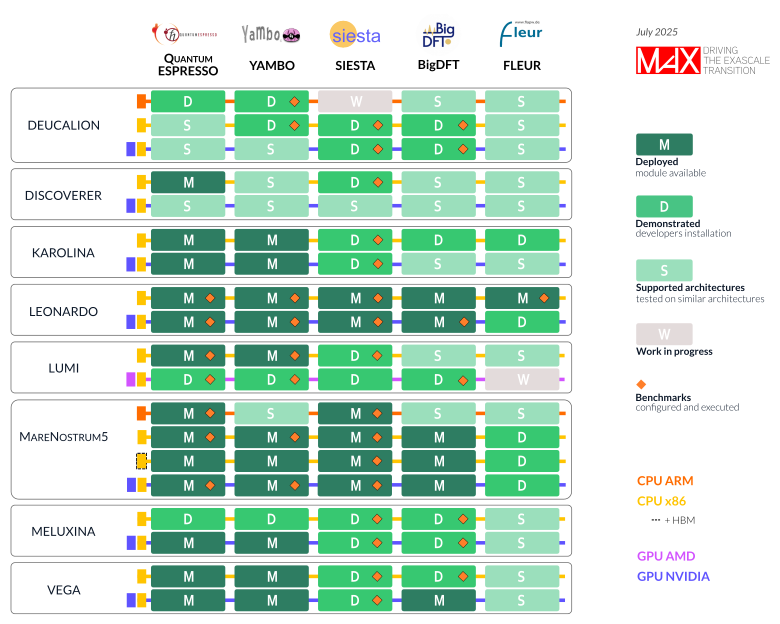
The figure below shows where we are today. MaX lighthouse applications are running on heterogeneous EuroHPC systems with high parallel efficiency. In many cases they are deployed and the modules are available to users (M, dark green), or demonstrated by the developers and ready for installation (D). Almost all architectures are now supported (S) and are ready for automatic deployment. EuroHPC Continuous Integration - Continuous Deployment procedures (CI/CD) are in the design and development phase; collaborations with CASTIEL2, other CoEs, and the Hosting Entities (HPC centres) are underway.
Throughout the entire project lifetime, MaX will continue to deploy its lighthouse codes on pre- and exascale machines of the European HPC ecosystem, allowing users to solve outstanding scientific problems at unprecedented scales and degrees of accuracy.
Enabling the exascale transition
Achieving exascale performances requires adopting software solutions that can disrupt the structure of legacy codes:
Profiling
Fundamental to identify and solve the bottlenecks of the lighthouse codes, and to evaluate both the exploitation of the machine architecture (FLOPS) and the energetic efficiencies (watt).
Programming paradigms
Essential to increasing the performances of the lighthouse codes on pre- and exascale architectures, through the improvement of code parallelization using standard OpenMP and MPI paradigms (CPUs) and the exploitation of new paradigms as OmpSS and CUDA (GPUs).
Libraries
Further developed to demonstrate the portability of performances across different accelerated technologies. Libraries are developed with Domain Specific Libraries (DSL) and Kernel libraries module.
Co-design
To support the evolution of sophisticated HPC architectures by enabling data and knowledge transfer between the hardware manufacturers (architecture vendors) and the scientists (scientific application developers, programming paradigm specialists, software tool developers) involved in many fields of computational materials science. Here, hardware and software do not act as independent agents, but strongly interact with one another.
MaX is on a mission to push the frontiers of HPC in the materials domain by:
-
Releasing new efficient and optimized versions of its lighthouse codes;
-
Developing libraries and modules that can be shared by different open source codes, different communities, and architecture vendors;
-
Facilitating feedback between scientists and developers;
-
Disseminating best practice through the organization of schools and workshops, the promotion of new collaborations with other CoEs, and the ease in accessing HPC facilities through PRACE initiatives.