
13 March 2025
Boosting collective communications with HPCX-MPI in Quantum ESPRESSO


MaX team achieves a significant performance improvement in the collective communications of Quantum ESPRESSO on the LEONARDO supercomputer by using NVIDIA’s HCOLL library from HPCX-MPI.
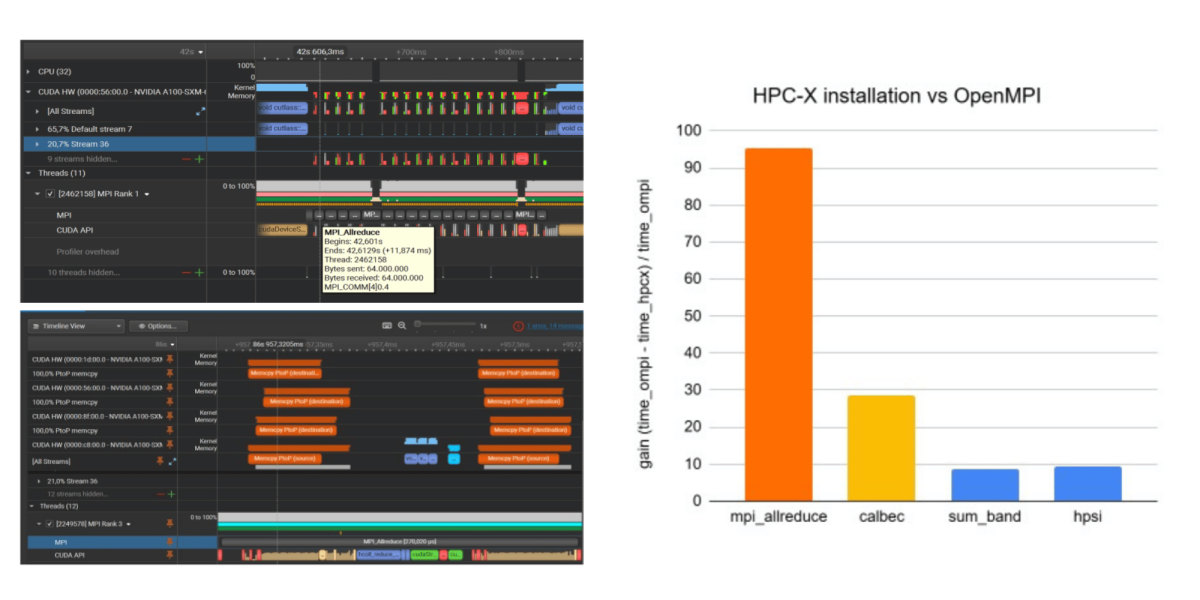
Performance improvement with HPCX-MPI in QuantumESPRESSO. Left panel shows the the NSight Systems trace of MPI_Allreduce communications in QuantumESPRESSO installed with OpenMPI (top panel) and HPCX-MPI (bottom panel). The brown event labelled as Memcpy P2P identifies buffer copies between GPU memories triggered by MPIcommunications, thus showing that HPCX-MPI supports awareness in collectives, while OpenMPI triggers D2H and H2D data copies. Right panel: % gain in time to solution for mpi_allreduce and selected routines in the grir443 simulation system (hpcx for allreduce optimization) distributed over 4 nodes; the reference is a previous Leonardo installation based on OpenMPI.
In heterogeneous computing, where both a CPU (host) and a GPU (device) work together, data must often be transferred between the two. However, these data transfers can be a major performance bottleneck. This happens for a variety of reasons:
1. CPU-GPU Data Transfer Overhead
- CPUs and GPUs have separate memory spaces (unless using unified memory).
- The CPU uses main system RAM, while the GPU has dedicated VRAM.
- Data must be explicitly copied from the host to the device before GPU computation and then copied back afterward.
- These memory transfers occur over the PCIe (Peripheral Component Interconnect Express) bus, which has limited bandwidth compared to the GPU’s high-speed internal memory.
2. High Latency and Bandwidth Limitations
- PCIe bandwidth is much lower than the memory bandwidth available inside a GPU.
- The time spent waiting for data transfers can sometimes outweigh the actual computation time.
3. Synchronization Overhead
- Some computations require frequent data exchange between CPU and GPU, leading to stalling—the CPU or GPU must wait for data before continuing.
- Synchronizing memory between the host and device introduces additional delays.
To prevent bottlenecks in high-performance computing programs, developers use CUDA (Compute Unified Device Architecture), a parallel computing platform and programming model created by NVIDIA that allows to use NVIDIA GPUs for general-purpose computing (beyond graphics), often referred to as GPGPU (General-Purpose GPU computing).
CUDA allows GPUs to communicate directly with each other over a high-speed connection. For this to work efficiently, a special version of MPI (called CUDA-aware MPI) is needed. This version can send and receive data directly between GPU memories, without first copying it to the CPU memory, which saves time and improves performance.
MaX lighthouse code QuantumESPRESSO supports CUDA-aware communications by design. Yet, performance issues have been observed in intra-node collective communications when using the OpenMPI implementation configured with Mellanox HCOLL library, a high-performance collective communication library specifically designed to optimize collective operations through hardware acceleration and network topology awareness.
Recently, the MaX team achieved a significative performance improvement in the collective communications of Quantum ESPRESSO on the LEONARDO supercomputer by adopting the HCOLL library from NVIDIA’s HPCX-MPI, which demonstrated to fully support GPUDirect communications via NVLink on the LEONARDO A100 accelerators.
In its third funding phase, MaX is working to tackle the technical challenges towards exascale computing and achieve high performance in its heterogeneous computing applications for materials science. In this framework, the ability to move data efficiently is just as important as raw computing power. Boosting collective communications in heterogeneous computing applications is key to achieving higher performance, better energy efficiency, and scalability for the next generation of supercomputers.